







Ensuring Your Judging Practices are Fair and Equitable
One of the most challenging aspects of running an awards, scholarship, or abstracts selection process is to demonstrate that the judging is fair and unbiased. Applicants generally expect that they will have an equal weighting against all other applicants that they are competing with.
Failure to ensure a proper judging process can backfire immensely. In 2014, a customer reached out to OpenWater because one of their applicants, a non-winner, requested a refund of their application fee. The applicant claimed that had their submission actually been judged, they would have won. Fortunately, the customer used the OpenWater platform and followed best judging practices and was able to provide proof of a fair evaluation.
In this post we will outline some of these best practices, as well as a few pitfalls to avoid when it comes to designing your judging process.
Judging Criteria
Above all else, the most important aspect to ensuring a fair judging process is a quality judging criteria. The best form of judging is a rubric-style where you select 3 to 5 criteria of a submission and ask the reviewer to score each of those criteria on a 1 to 5 or 1 to 10 scale, higher number being the best.
For example, if you are judging a marketing campaign submission, you might want to ask:
Rate the following criteria on a scale of 1 to 10, 10 being the best:
- Rate this marketing campaign’s originality.
- Rate this marketing campaign’s impact and effectiveness.
- Rate this marketing campaign’s longevity.
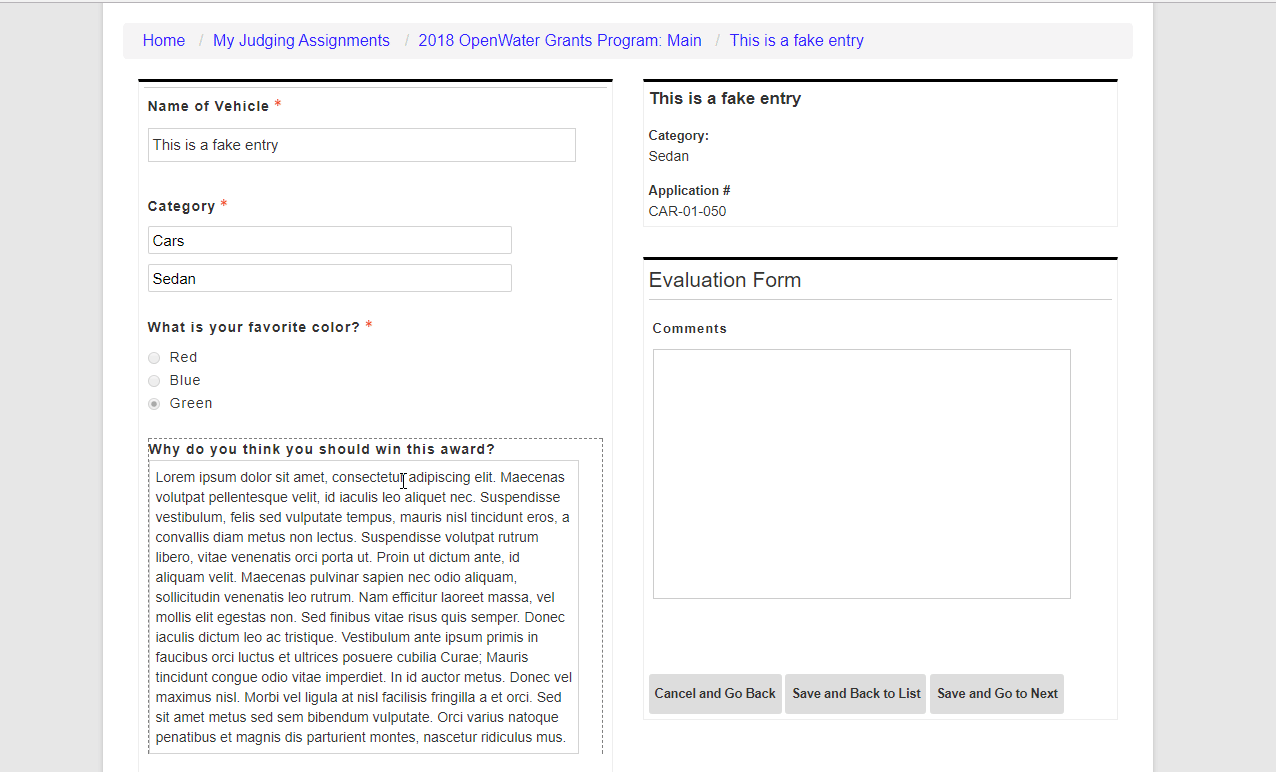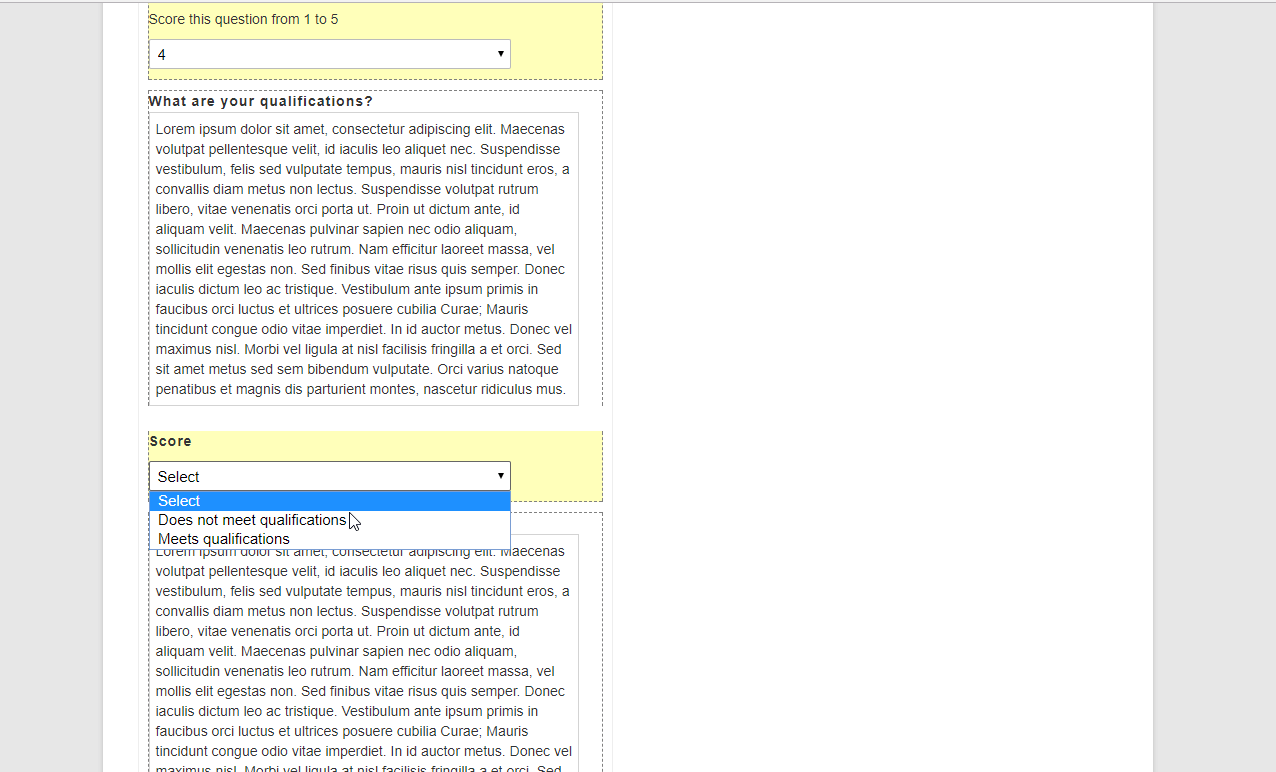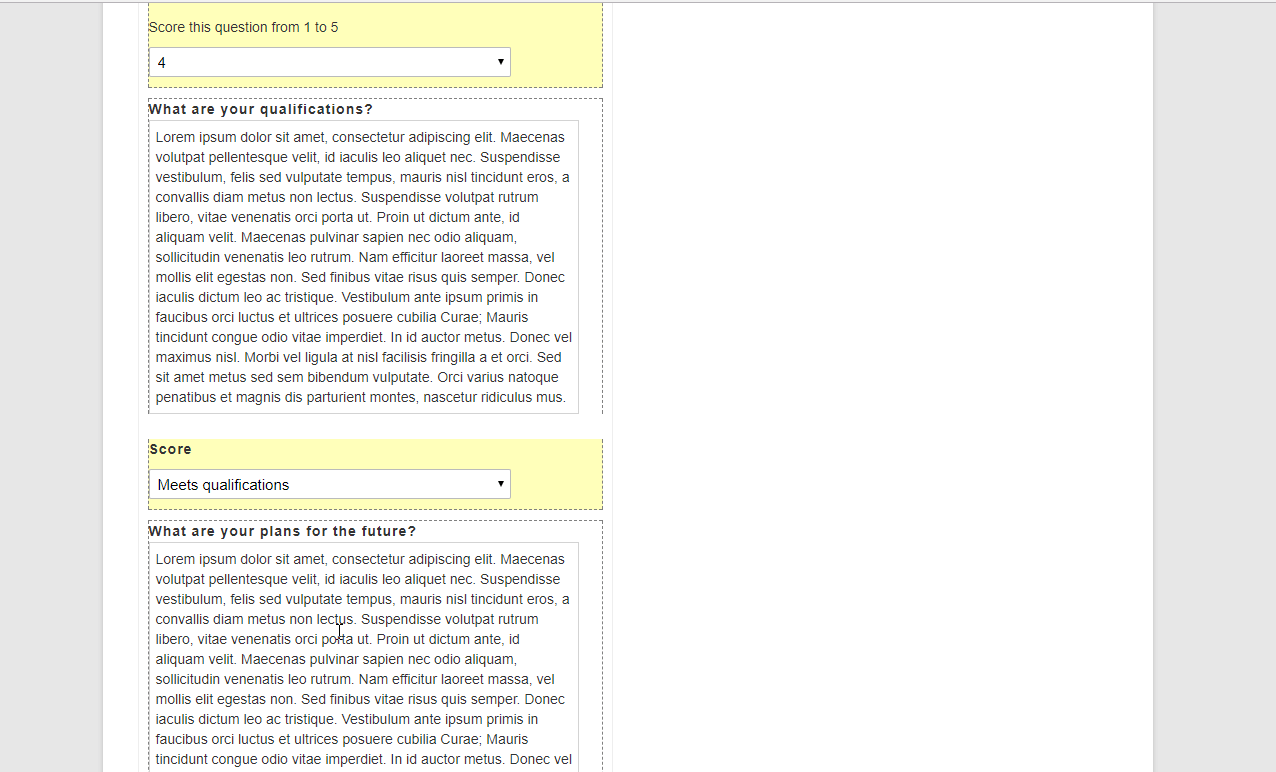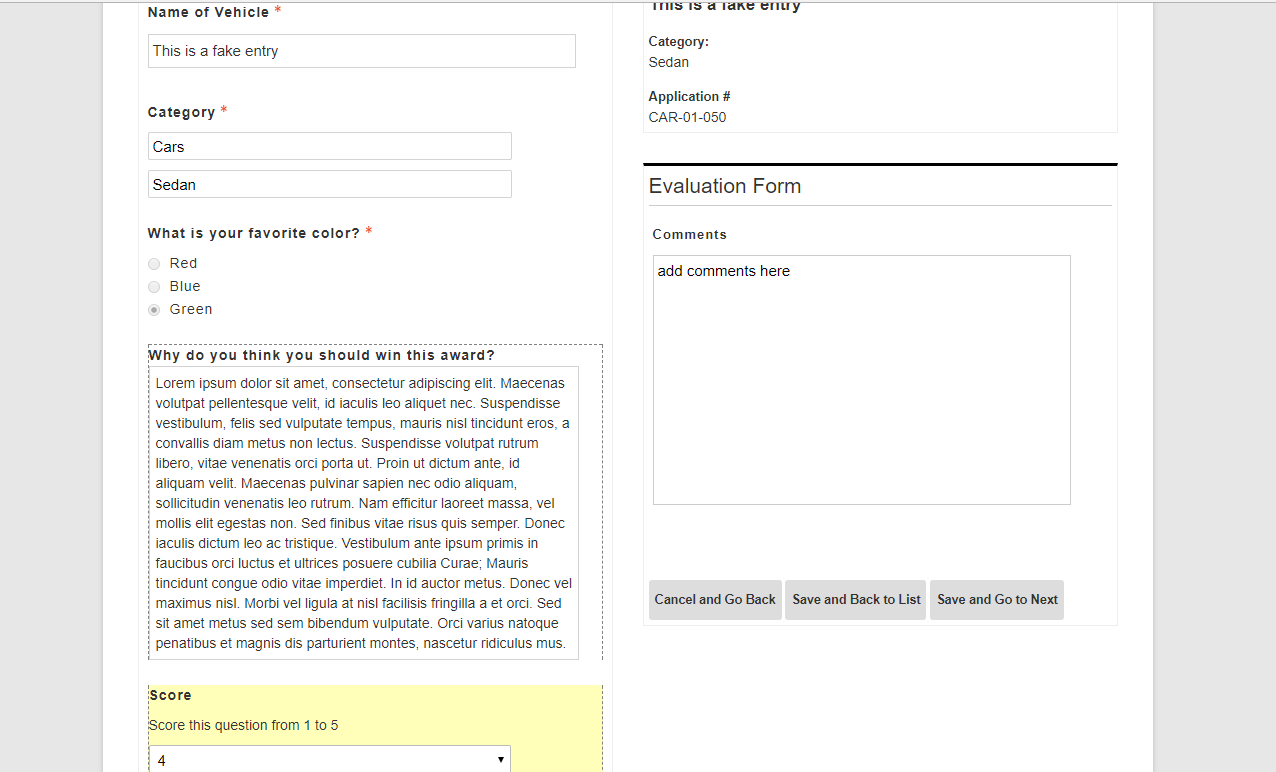
Depending on your scale, you may weigh some criteria heavier than others. But if all of the above are weighed equally, then the maximum score for a submission is 30 points by a single reviewer. We will cover judging pools in a later section of this post.
Some pitfalls to avoid are generic, single aggregate questions such as: “How do you feel about this submission overall?” Questions like these do not really capture the finer points of a submission. However, one method that is typical is if you have multiple rounds of review where the first round is simply a Pass/Fail of “Do you wish to see this submission again?” — And those that received a universal No can be culled. This is effective if you are dealing with an exceptionally high volume of submissions and do not wish to spend time on very poor quality entries.
An alternative judging approach is Ranking. This is where you choose your favorite submissions, or set the order of submissions from favorite to least favorite. This is only recommended in a multi-round review process and would be recommended in a Finalist round where everyone already went through a rubric style review and then narrowed down to 3 to 5 finalists per category. In that scenario, a ranking would be an effective closer.
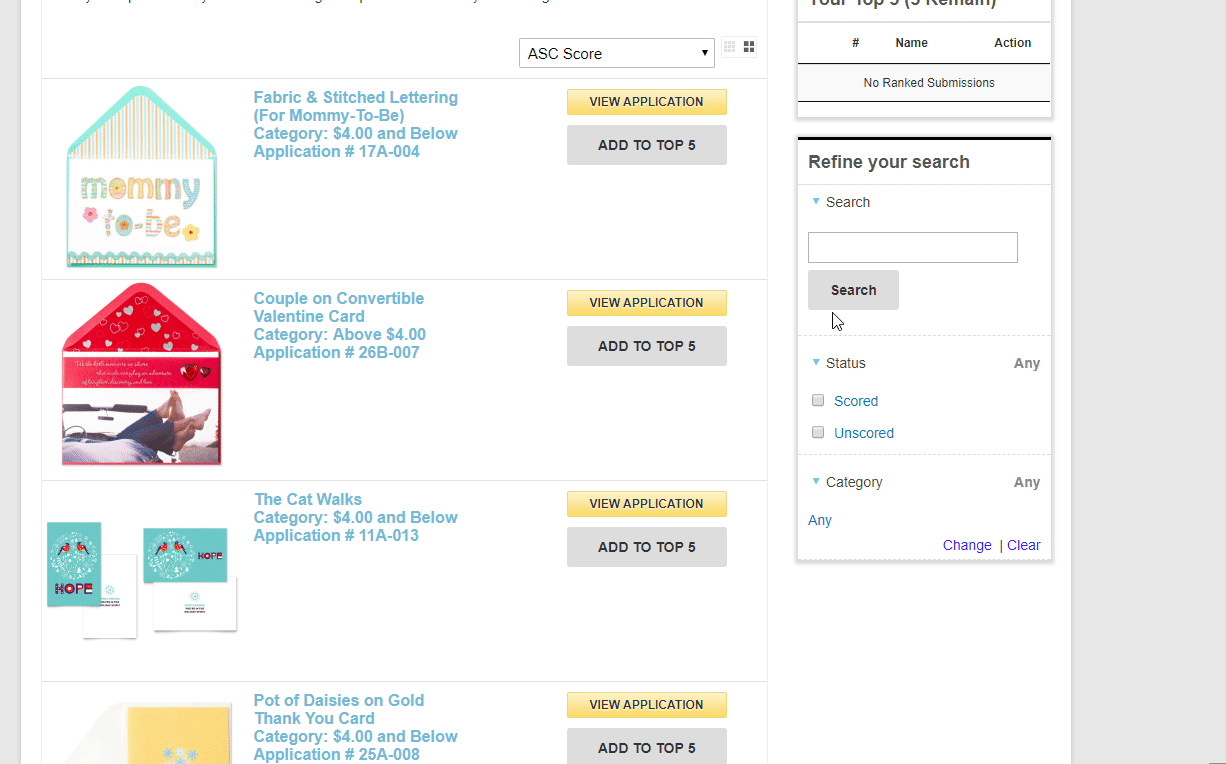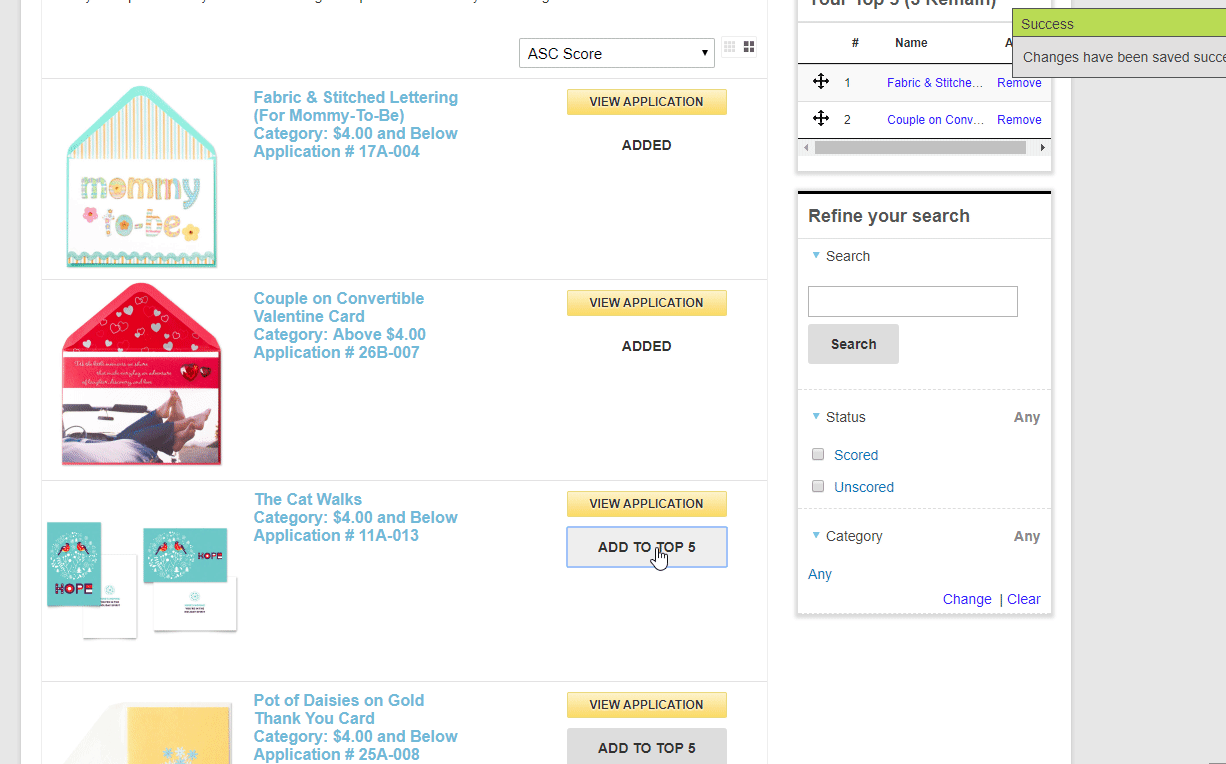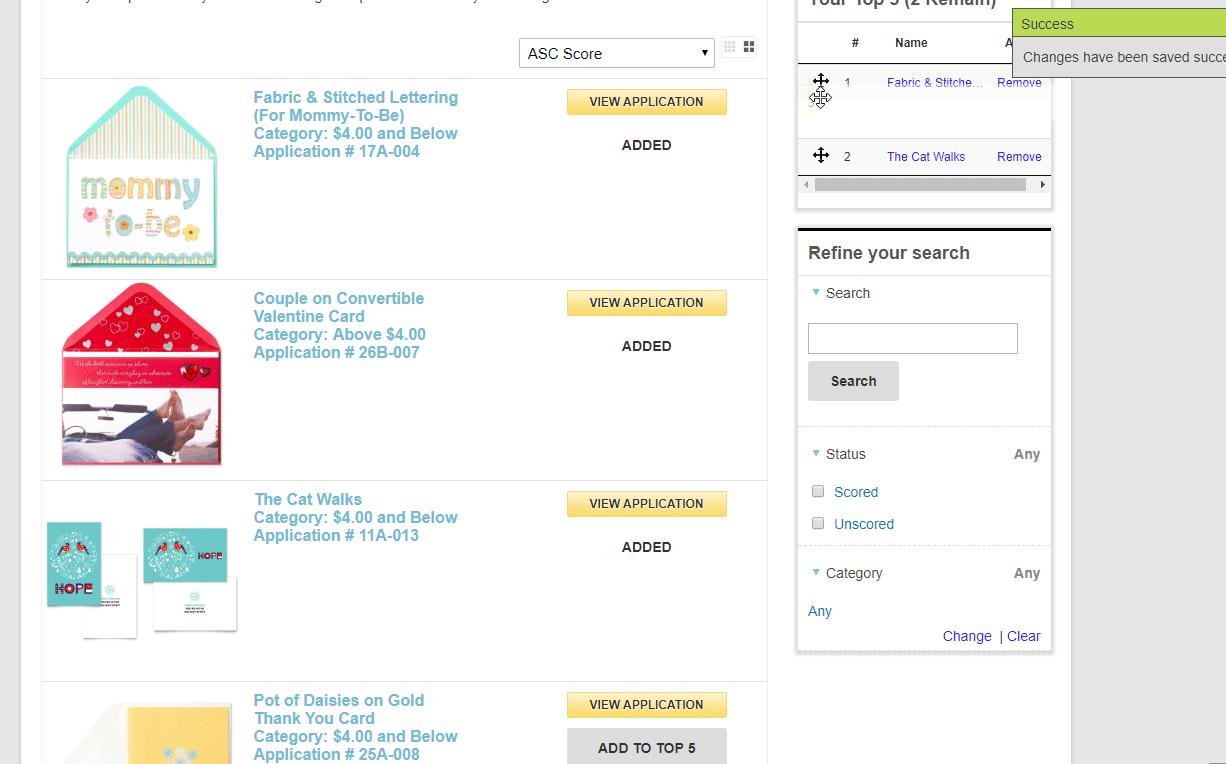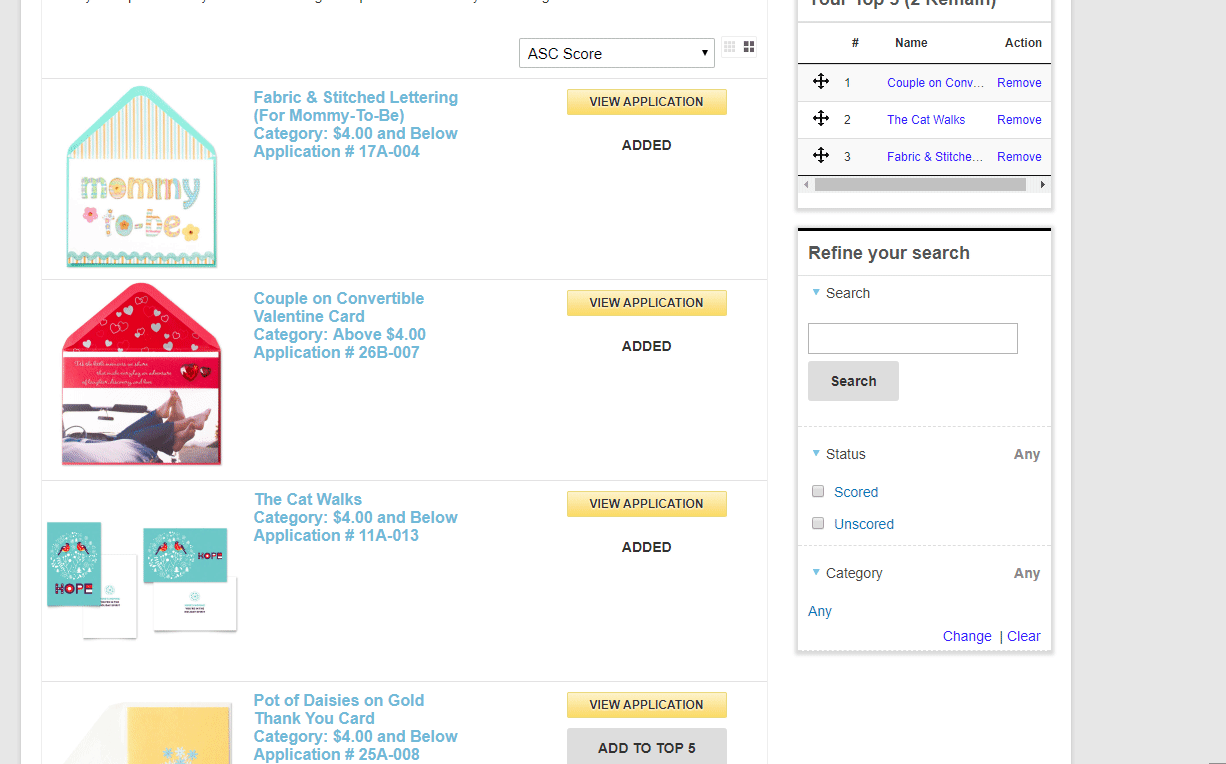
Judging pools
Some organizations are concerned about a lack of diversity when it comes to the final selection outcome. In 2017, ElectronConf, a popular technical conference heavily sponsored by Github cancelled their own conference when not a single female speaker was selected. The decision was controversial because their review process was completely blind.
Unless the program you are running is designed to increase diversity, the outcome of the results are largely beyond your control. Instead, consider focusing your efforts on creating a diverse judging panel. Seek out experts in the field, but do your best to cover a wide range of backgrounds and demographics. This is important because each reviewer brings with them a wealth of experience both in their fields of study and personal life. If a judging panel lacks different perspectives, then the outcome may be skewed in a way.
It is recommended to have at least 3 judges per submission. If possible, have the same judges review the same submissions as a group. If judges are distributed completely randomly and they do not all score the same submissions, it might be the case where some judges are naturally harsher than others. This could skew the results. Some organizations, as a workaround, will automatically remove the highest and lowest score of each submission to exclude any outliers, though I do not find this approach as appealing.
Blind Judging
In a perfect world, you would be able to institute a blind judging. With the OpenWater platform, this is a built-in option that you can enable. If the judges cannot see any names or personally identifying information about the submitter, they can judge the application solely on its work. However, the nature of your program may make this infeasible, or if the community is small, everyone knows everyone’s work anyway.
As an alternative, you should allow your reviewers to recuse themselves from reviewing an entry that they have a conflict of interest with.
But even with blind judging and judges recusing themselves if there is a conflict of interest, people are known to have an unconscious bias. For example, just looking at the length of a CV might influence how you view an application. Here at OpenWater, we have seen some organizations, particularly involved in Fellowships and Scholarships, send their entire judging pool through Unconscious Bias Training webinars prior to the beginning of judging.
The Selection
Once all of the scorecards have been collected, you should tabulate the averages of all the scorecards which will result in a list of top performers. You can simply select the winner(s) from here.
However, the most common method for deciding who a winner is, surprisingly, is judges coming together and talking about the submissions over a conference call in an informal manner.
I do not think it is realistic to do away with this entirely, and it is probably fine for plenty of programs out there. But more and more often, organizations are asking us for advice about moving to a more formal process.
The problem with just a pure conversation is that some people in the group may tend to dominate the discussion. The submissions they are advocating for may receive an unfair advantage. Try to structure the discussion in a way where everyone is included and provided an equal amount of time to share their thoughts.
But in many cases, a discussion must be had. We strongly encourage that all the judges at least score the submissions on their own first, using the rubric style we outlined above. But the results from that scoring is what can be used to foster that discussion. It provides numerical values for each submission and people can argue from there.
We hope this provides some insight into judging practices and what you can do to ensure you are being as fair as possible.
For more details on how OpenWater can be configured to manage a complex judging process visit our helpcenter.

Best Practices for Setting up a Virtual Conference Abstract Collection Workflow: Part 1
Creating engagement between your virtual event attendees and exhibitors/sponsors
Filter resources
Explore Posts by Topic
Best Resources
The Ultimate Guide to Awards Management
